
-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Thursday, December 6th
Time: 2:15pm - 4:00pm
Venue: Hall B5(2) (5F, B Block)
Session Chair(s): Shahram Izadi, Google, United States of America
Modeling Hair from an RGB-D Camera
Abstract: Creating complete and realistic 3D hairs to closely match the real-world inputs remains challenging. With the increasing popularity of lightweight depth cameras featured in devices such as iPhone X, Intel RealSense, and DJI drones, additional geometric cues can be easily obtained to facilitate many entertainment applications, for example, the Animated Emoji. In this paper, we introduce a fully automatic data-driven approach to model the hair geometry and compute a complete strand-level 3D hair model that closely resembles both the fusion model and the hair textures using a single RGB-D camera. Our method heavily exploits the geometric cues offered in the depth channel and leverages exemplars in 3D hair database for high-fidelity hair synthesis. The core of our method is a local-similarity based search and synthesis algorithm that simultaneously reasons about the hair geometry, strands connectivity, strand orientation, and hair structural plausibility. We demonstrate the efficacy of our method using a variety of complex hairstyles and compare our method with prior arts.
Authors/Presenter(s): Meng Zhang, State Key Lab of CG&CAD, Zhejiang University, China
Pan Wu, State Key Lab of CG&CAD, Zhejiang University, China
Hongzhi Wu, State Key Lab of CG&CAD, Zhejiang University, China
Yanlin Weng, State Key Lab of CG&CAD, Zhejiang University, China
Youyi Zheng, Zhejiang University and ZJU-FaceUnity Joint Lab of Intelligent Graphics, China
Kun Zhou, Zhejiang University and ZJU-FaceUnity Joint Lab of Intelligent Graphics, China

Video to Fully Automatic 3D Hair Model
Abstract: Imagine taking a selfie video with your mobile phone and getting as output a 3D model of your head (face and 3D hair strands) that can be later used in VR, AR, and any other domain. State of the art hair reconstruction methods allow either a single photo (thus compromising 3D quality), or multiple views but require manual user interaction (manual hair segmentation and capture of fixed camera views that span full 360 angles). In this paper, we present a system that can create a reconstruction from any video (even a selfie video), completely automatically, and we don't require specific views since taking your -90 degree, 90 degree, and full back views is not feasible in a selfie capture. In the core of our system, in addition to the automatization components, hair strands are estimated and deformed in 3D (rather than 2D as in state of the art) thus enabling superior results. We present qualitative, quantitative, and Mechanical Turk human studies that support the proposed system, and show results on diverse variety of videos (8 different celebrity videos, 9 selfie mobile videos, spanning age, gender, hair length, type, and styling).
Authors/Presenter(s): Shu Liang, University of Washington, United States of America
Xiufeng Huang, Owlii, China
Xianyu Meng, Owlii, China
Kunyao Chen, Owlii, China
Linda Shapiro, University of Washington, United States of America
Ira Kemelmacher-Shlizerman, University of Washington, Facebook, United States of America

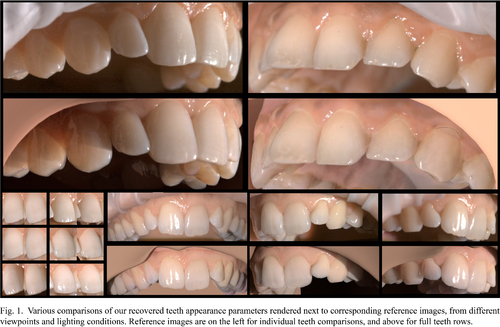
Appearance Capture and Modeling of Human Teeth
Abstract: Recreating the appearance of humans in virtual environments for the purpose of movie, video game, or other types of production involves the acquisition of geometry representation of the human body and its scattering parameters which express the interaction between geometry and light propagated throughout the scene. Teeth appearance is defined not only by the light and surface interaction, but also by its internal geometry and the intra-oral environment posing its own unique set of challenges. Therefore, we present a system specifically designed for capturing the optical properties of live human teeth such that they can be realistically re-rendered in Computer Graphics. We acquire our data in vivo in a conventional multiple camera and light source setup and use exact geometry segmented from intra-oral scans. To simulate the complex interaction of light in the oral cavity during inverse rendering we employ a novel pipeline based on derivative path tracing with respect to both optical properties and geometry of the inner dentin surface. The resulting estimates of the global derivatives are used to extract parameters in a joint numerical optimization. The final appearance faithfully recreates the acquired data and can be directly used in conventional path tracing frameworks.
Authors/Presenter(s): Zdravko Velinov, Disney Research and Rheinische Friedrich-Wilhelms-Universität Bonn, Germany; Rheinische Friedrich-Wilhelms-Universität Bonn, Germany, Switzerland
Marios Papas, Disney Research, Switzerland
Derek Bradley, Disney Research, Switzerland
Paulo Gotardo, Disney Research, Switzerland
Parsa Mirdehghan, Disney Research, Switzerland
Steve Marschner, Cornell University, United States of America
Jan Novak, Disney Research, Switzerland
Thabo Beeler, Disney Research, Switzerland
3D Hair Synthesis Using Volumetric Variational Autoencoders
Abstract: Recent advances in single-view 3D hair digitization have made the creation of high-quality CG characters scalable and accessible to end-users, enabling new forms of personalized VR and gaming experiences. To handle the complexity and variety of hair structures, most cutting-edge techniques rely on the successful retrieval of a particular hair model from a comprehensive hair database. Not only are the aforementioned data-driven methods storage intensive, but they are also prone to failure for highly unconstrained input images, exotic hairstyles, failed face detection. Instead of using a large collection of 3D hair models directly, we propose to represent the manifold of 3D hairstyles implicitly through a compact latent space of a volumetric variational autoencoder (VAE). This deep neural network is trained with volumetric orientation field representations of 3D hair models and can synthesize new hairstyles from a compressed code. To enable end-to-end 3D hair inference, we train an additional regression network to predict the codes in the VAE latent space from any input image. Strand-level hairstyles can then be generated from the predicted volumetric representation. Our fully automatic framework does not require any ad-hoc face fitting, intermediate classification and segmentation, or hairstyle database retrieval. Our hair synthesis approach is significantly more robust than and can handle a much wider variation of hairstyles than state-of-the-art data-driven hair modeling techniques w.r.t. challenging inputs, including photos that are low-resolution, overexposured, or contain extreme head poses. The storage requirements are minimal and a 3D hair model can be produced from an image in a second. Our evaluations also show that successful reconstructions are possible from highly stylized cartoon images, non-human subjects, and pictures taken from the back of a person. Our approach is particularly well suited for continuous and plausible hair interpolation between very different hairstyles.
Authors/Presenter(s): Shunsuke Saito, University of Southern California, Pinscreen, United States of America
Liwen Hu, University of Southern California, Pinscreen, United States of America
Chongyang Ma, Snap Inc., United States of America
Hikaru Ibayashi, University of Southern California, United States of America
Linjie Luo, Snap Inc., United States of America
Hao Li, University of Southern California, Pinscreen, United States of America

