
-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Wednesday, December 5th
Time: 2:15pm - 4:00pm
Venue: Hall B5(2) (5F, B Block)
Session Chair(s): Ariel Shamir, The Interdisciplinary Center, Israel
Deep Unsupervised Pixelization
Abstract: In this paper, we present a novel unsupervised learning method for pixelization. Due to the difficulty in creating pixel art, preparing the paired training data for supervised learning is impractical. Instead, we propose a unsupervised learning framework to circumvent such difficulty. We leverage the dual nature of the pixelization and depixelization, and model these two tasks in the same network in a bi-directional manner with the input itself as training supervision. These two tasks are modeled as a cascaded network which consists of three stages for different purposes. GridNet transfers the input image into multi-scale grid-structured images with different aliasing effects. PixelNet associated with GridNet to synthesize pixel arts with sharp edges and perceptually optimal local structures. DepixelNet connects the previous network and aims to recover the pixelized result to the original image. For the sake of unsupervised learning, the mirror loss is proposed to hold the reversibility of feature representations in the process. In addition, adversarial, L1, and gradient losses are involved in the network to obtain pixel arts by retaining color correctness and smoothness. We show that our technique can synthesize crisper and perceptually more appropriate pixel arts than state-of-the-art image downscaling methods. We evaluate the proposed method with extensive experiments over many images. The proposed method outperforms state-of-the-art methods in terms of visual quality and user preference.
Authors/Presenter(s): Shengfeng He, South China University of Technology, China
Qianshu Zhu, South China University of Technology, China
Yinjie Tan, South China University of Technology, China
Guoqiang Han, South China University of Technology, China
Tien-Tsin Wong, the Chinese University of Hong Kong, Hong Kong
Chu Han, the Chinese University of Hong Kong, Hong Kong
Qiang Wen, South China University of Technology, China
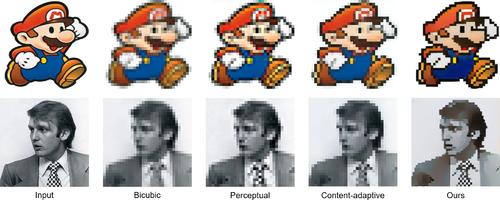
CariGAN: Unpaired Photo-to-Caricature Translation
Abstract: Facial caricature is an art form of drawing faces in an exaggerated way to convey humor or sarcasm. In this paper, we propose the first Generative Adversarial Network (GAN) for unpaired photo-to-caricature translation, which we call ``CariGANs". It explicitly models geometric exaggeration and appearance stylization using two components: CariGeoGAN, which only models the geometry-to-geometry transformation from face photos to caricatures, and CariStyGAN, which transfers the style appearance from caricatures to face photos without any geometry deformation. In this way, a difficult cross-domain translation problem is decoupled into two easier tasks. The perceptual study shows that caricatures generated by our CariGANs are closer to the hand-drawn ones, and at the same time better persevere the identity, compared to state-of-the-art methods. Moreover, our CariGANs allow user controlling the shape exaggeration degree and changing the color/texture style by tuning the parameters or giving an example caricature.
Authors/Presenter(s): Kaidi Cao, Tsinghua University, China
Jing Liao, City University of Hong Kong, Microsoft Research, Hong Kong
Lu Yuan, Microsoft Research, China

DeepLens: Shallow Depth Of Field From A Single Image
Abstract: We aim to generate high resolution shallow depth-of-field (DoF) images from a single all-in-focus image with controllable focal distance and aperture size. To achieve this, we propose a novel neural network model comprised of a depth prediction module, a lens blur module, and a guided upsampling module. All modules are differentiable and are learned from data. To train our depth prediction module, we collect a dataset of 2462 RGB-D images captured by mobile phones with a dual-lens camera, and use existing segmentation datasets to improve border prediction. We further leverage a synthetic dataset with known depth to supervise the lens blur and guided upsampling modules. The effectiveness of our system and training strategies are verified in the experiments. Our method can generate high-quality shallow DoF images at high resolution, and produces significantly fewer artifacts than the baselines and existing solutions for single image shallow DoF synthesis. Compared with the iPhone portrait mode, which is a state-of-the-art shallow DoF solution based on a dual-lens depth camera, our method generates comparable results, while allowing for greater flexibility to choose focal points and aperture size, and is not limited to one capture setup.
Authors/Presenter(s): Lijun Wang, Dalian University of Technology, Adobe Research, China
Xiaohui Shen, ByteDance AI Lab, United States of America
Jianming Zhang, Adobe Research, United States of America
Oliver Wang, Adobe Research, United States of America
Zhe Lin, Adobe Research, United States of America
Chih-Yao Hsieh, Adobe Systems, United States of America
Sarah Kong, Adobe Systems, United States of America
Huchuan Lu, Dalian University of Technology, China

Invertible Grayscale
Abstract: Once a color image is converted to grayscale, it is a common belief that the original color cannot be fully restored, even with the state-of-the-art colorization methods. In this paper, we propose an innovative method to synthesize invertible grayscale. It is a grayscale image that can fully restore its original color. The key idea here is to encode the original color information into the synthesized grayscale, in a way that users cannot recognize any anomalies. We propose to learn and embed the color-encoding scheme via a convolutional neural network (CNN). It consists of an encoding network to convert a color image to a grayscale, and a decoding network to invert the grayscale to color. We then design a loss function to ensure the trained network possesses three required properties: (a) the color invertibility, (b) the grayscale conformity, and (c) the resistance to quantization error. We have conducted intensive quantitative experiments and user studies over a large amount of color images to validate the proposed method. Regardless of the genre and the content of the color input, convincing results are obtained in all cases.
Authors/Presenter(s): Menghan XIA, The Chinese University of Hong Kong, Hong Kong
Xueting LIU, The Chinese University of Hong Kong, Hong Kong
Tien-Tsin WONG, The Chinese University of Hong Kong, Hong Kong

