-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Friday, December 7th
Time: 9:00am - 10:45am
Venue: Hall B5(2) (5F, B Block)
Session Chair(s): Youyi Zheng, ZJU, China
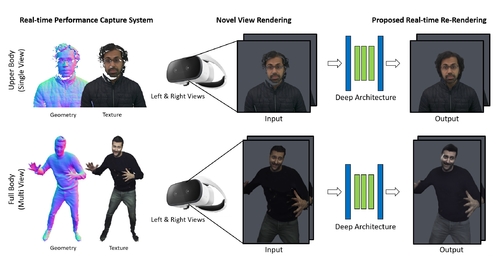
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Abstract: Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. This enhancement of the final rendering in real-time, brings us a final high quality result. We call this approach neural (re-)rendering, and our live system ``LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 capture. Through extensive experimentation, we demonstrate how our system generalizes across subjects.
Authors/Presenter(s): Ricardo Martin-Brualla, Google, United States of America
Rohit Pandey, Google, United States of America
Shuoran Yang, Google, United States of America
Pavel Pidlypenskyi, Google, United States of America
Jonathan Taylor, Google, United States of America
Julien Valentin, Google, United States of America
Sameh Khamis, Google, United States of America
Philip Davidson, Google, United States of America
Anastasia Tkach, Google, United States of America
Peter Lincoln, Google, United States of America
Adarsh Kowdle, Google, United States of America
Christoph Rhemann, Google, United States of America
Dan B. Goldman, Google, United States of America
Cem Keskin, Google, United States of America
Steve Seitz, Google, United States of America
Shahram Izadi, Google, United States of America
Sean Fanello, Google, United States of America
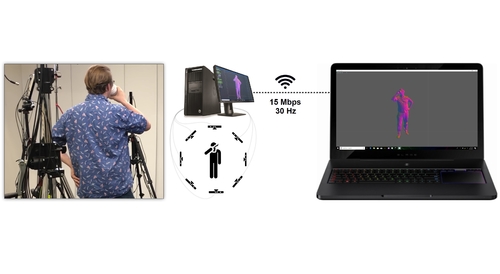
Real-time Compression and Streaming of 4D Performances
Abstract: We introduce a realtime compression architecture for 4D performance capture that is two orders of magnitude faster than current state-of-the-art techniques, yet achieves comparable visual quality and bitrate. We note how much of the algorithmic complexity in traditional 4D compression arises from the necessity to encode geometry in a explicit model (i.e. a triangle mesh). In contrast, we propose an encoder that leverages implicit representations (namely a Signed Distance Function) to represent the observed geometry, as well as its changes through time. We demonstrate how SDFs, when defined in a local support (i.e. a block), admit a low-dimensional embedding due the innate geometric redundancies in their representation. We then propose an optimization that takes Truncated SDF (i.e. TSDF) found in most rigid/non-rigid reconstruction pipelines, and efficiently project each TSDF block in the SDF latent space. This results in a collection of low entropy tuples that can be effectively quantized and symbolically encoded. On the decoder side, to avoid the typical artifacts of block-based coding, we also propose a variational optimization that recovers the quantization residuals in order to penalize unsightly discontinuities in the decompressed signal. This optimization is expressed in the SDF latent embedding, and hence can also be performed efficiently. We demonstrate our compression/decompression architecture by realizing, to the best of our knowledge, the first system for streaming a real-time captured 4D performance on consumer-level networks.
Authors/Presenter(s): Danhang Tang, Google, United States of America
Mingsong Dou, Google, United States of America
Peter Lincoln, Google, United States of America
Philip Davidson, Google, United States of America
Kaiwen Guo, Google, United States of America
Jonathan Taylor, Google, United States of America
Sean Fanello, Google, United States of America
Cem Keskin, Google, United States of America
Adarsh Kowdle, Google, United States of America
Sofien Bouaziz, Google, United States of America
Shahram Izadi, Google, United States of America
Andrea Tagliasacchi, Google, United States of America
Deep Blending for Free-Viewpoint Image-Based Rendering
Abstract: Free-viewpoint image-based rendering (IBR) is a standing challenge. IBR methods combine warped versions of input photos to synthesize a novel view. The image quality of this combination is directly affected by geometric inaccuracies of multi-view stereo (MVS) reconstruction and by view- and image-dependent effects that produce artifacts when contributions from different input views are blended. We present a new deep learning approach to blending for IBR, in which we use held-out real image data to learn blending weights to combine input photo contributions. Our Deep Blending method requires us to address several challenges to achieve our goal of interactive free-viewpoint IBR navigation. We first need to provide sufficiently accurate geometry so the Convolutional Neural Network (CNN) can succeed in finding correct blending weights. We do this by combining two different MVS reconstructions with complementary accuracy vs. completeness tradeoffs. To tightly integrate learning in an interactive IBR system, we need to adapt our rendering algorithm to produce a fixed number of input layers that can then be blended by the CNN. We generate training data with a variety of captured scenes, using each input photo as ground truth in a held-out approach. We also design the network architecture and the training loss to provide high quality novel view synthesis, while reducing temporal flickering artifacts. Our results demonstrate free-viewpoint IBR in a wide variety of scenes, clearly surpassing previous methods in visual quality, especially when moving far from the input cameras.
Authors/Presenter(s): Peter Hedman, UCL, United Kingdom
Julien Philip, Inria, Université Côte d’Azur, France
True Price, UNC Chapel Hill, United States of America
Jan-Michael Frahm, UNC Chapel Hill, United States of America
George Drettakis, Inria, Université Côte d’Azur, France
Gabriel Brostow, UCL / Niantic, United Kingdom

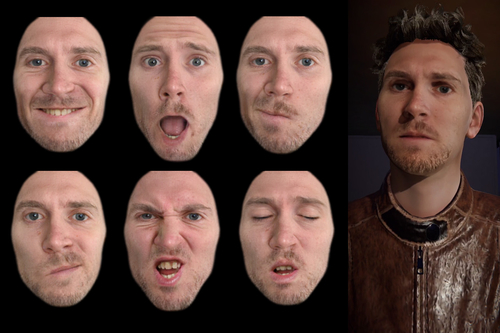
paGAN: Real-time Avatars Using Dynamic Textures
Abstract: With the rising interest in personalized VR and gaming experiences comes the need to create high quality 3D avatars that are both low-cost and variegated. Due to this, building dynamic avatars from a single unconstrained input image is becoming a popular application. While previous techniques that attempt this require multiple input images or rely on transferring dynamic facial appearance from a source actor, we are able to do so using only one 2D input image without any form of transfer from a source image. We achieve this using a new conditional Generative Adversarial Network design that allows fine-scale manipulation of any facial input image into a new expression while preserving its identity. Our photoreal avatar GAN (paGAN) can also synthesize the unseen inner mouth region and control the eye-gaze direction of the output, as well as produce the final image from a novel viewpoint. The method is even capable of generating fully-controllable temporally stable video sequences, despite not using temporal information during training. After training, we can use our network to produce dynamic image-based avatars that are drive-able on mobile devices in real time. To do this, we compute a fixed set of output images that correspond to key blendshapes, from which we extract textures in UV space. Using a user's expression blendshapes at run-time, we can linearly blend these key textures together to achieve the desired appearance. Furthermore, we can use the inner-mouth and eye textures produced by our network to synthesize on-the-fly avatar animations for those regions. Our work produces state-of-the-art quality image and video synthesis, and is the first to our knowledge that is able to generate a dynamically textured avatar with an inner-mouth, all from a single image.
Authors/Presenter(s): Koki Nagano, Pinscreen, USC Institute for Creative Technologies, United States of America
Jaewoo Seo, Pinscreen, United States of America
Jun Xing, USC Institute for Creative Technologies, United States of America
Lingyu Wei, Pinscreen, United States of America
Zimo Li, University of Southern California, United States of America
Shunsuke Saito, University of Southern California, Pinscreen, United States of America
Aviral Agarwal, Pinscreen, United States of America
Jens Fursund, Pinscreen, United States of America
Hao Li, Pincreen, University of Southern California, United States of America