
-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Thursday, December 6th
Time: 2:15pm - 4:00pm
Venue: Hall B5(1) (5F, B Block)
Session Chair(s): Nobuyuki Umetani, Autodesk,
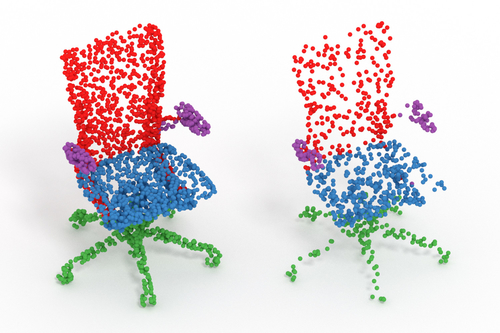
Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds
Abstract: Deep learning systems extensively use convolution operations to process input data. Though convolution is clearly defined for structured data such as images, this is not true for other data types such as sparse point clouds. Previous techniques have developed approximations to convolutions for restricted conditions. Unfortunately, their applicability is limited and cannot be used for general point clouds. We propose an efficient and effective method to learn convolutions for non-uniformly sampled point clouds, as they are obtained with modern acquisition techniques. Learning is enabled by four key novelties: first, representing the convolution kernel itself as a multilayer perceptron; second, phrasing convolution as a Monte Carlo integration problem, third, using this notion to combine information from multiple samplings at different levels; and fourth using Poisson disk sampling as a scalable means of hierarchical point cloud learning. The key idea across all these contributions is to guarantee adequate consideration of the underlying non-uniform sample distribution function from a Monte Carlo perspective. To make the proposed concepts applicable to real-world tasks, we furthermore propose an efficient implementation which significantly reduces the GPU memory required during the training process. By employing our method in hierarchical network architectures we can outperform most of the state-of-the-art networks on established point cloud segmentation, classification and normal estimation benchmarks. Furthermore, in contrast to most existing approaches, we also demonstrate the robustness of our method with respect to sampling variations, even when training with uniformly sampled training data only. To support the direct application of these concepts, we provide a ready-to-use TensorFlow implementation of these layers at https://github.com/viscom-ulm/MCCNN
Authors/Presenter(s): Pedro Hermosilla Casajus, Ulm University, Germany
Tobias Ritschel, University College London, Germany
Pere-Pau Vazquez, ViRVIG Reasearch Group, UPC Barcelona, Spain
Alvar Vinacua, Universitat Politecnica of CataViRVIG Reasearch Group, UPC Barcelonalunya, Spain
Timo Ropinski, Ulm University, Germany
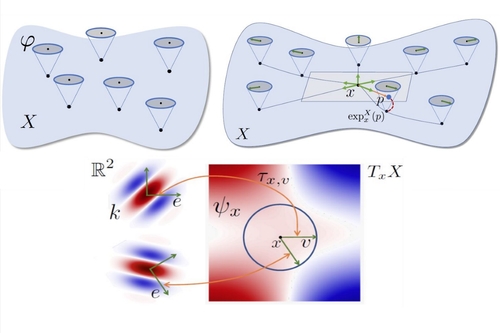
Multi-directional Geodesic Neural Networks via Equivariant Convolution
Abstract: We propose a novel approach for performing convolution of signals defined on curved surfaces and show its utility in a variety of geometric deep learning applications. Key to our construction is the notion of angular functions defined on the surface, which extend the classic real-valued signals, and which can be naturally convolved with real-valued template functions. As a result, rather than trying to fix a canonical orientation or only keeping the maximal response across all alignments of a 2D template at every point of the surface, as done in previous works, we show how information across all rotations can be kept across different layers of the neural network. Our construction allows, in particular, to propagate directional information, after convolution, across layers and thus different regions on the shape, leading to the notion of multi-directional geodesic convolution, or directional convolution for short. We first define directional convolution in the continuous setting, prove its key properties and then show how it can be implemented in practice, for shapes represented as triangle meshes. We evaluate directional convolution in a wide variety of learning scenarios ranging from classification of signals on surfaces, to shape segmentation and shape matching, where we show a significant improvement over several baselines.
Authors/Presenter(s): Adrien Poulenard, Ecole polytechnique, France
Maks Ovsjanikov, Ecole polytechnique, France
Adaptive O-CNN: A Patch-based Deep Representation of 3D Shapes
Abstract: We present an Adaptive Octree-based Convolutional Neural Network (Adaptive O-CNN) for efficient 3D shape encoding and decoding. Different from volumetric-based or octree-based CNN methods that represent a 3D shape with voxels in the same resolution, our method represents a 3D shape adaptively with octants at different levels and models the 3D shape within each octant with a planar patch. Based on this adaptive patch-based representation, we propose an Adaptive O-CNN encoder and decoder for encoding and decoding 3D shapes. The Adaptive O-CNN encoder takes the planar patch normal and displacement as input and performs 3D convolutions only at the octants at each level, while the Adaptive O-CNN decoder infers the shape occupancy and subdivision status of octants at each level and estimates the best plane normal and displacement for each leaf octant.As a general framework for 3D shape analysis and generation, the Adaptive O-CNN not only reduces the memory and computational cost, but also offers better shape generation capability than the existing 3D-CNN approaches. We validate the efficiency and effectiveness of Adaptive O-CNN in different shape analysis and generation tasks, including shape classification, 3D autoencoder, shape prediction from a single image, and shape completion for noisy and incomplete point clouds.
Authors/Presenter(s): Peng-Shuai Wang, Tsinghua University, Microsoft Research Asia, China
Chun-Yu Sun, Tsinghua University, Microsoft Research Asia, China
Yang Liu, Microsoft Research Asia, China
Xin Tong, Microsoft Research Asia, China

Robust Flow-Guided Neural Prediction for Sketch-Based Freeform Surface Modeling
Abstract: Sketching provides an intuitive user interface for communicating freeform shapes. While human observers can easily envision the shapes they intend to communicate, replicating this process algorithmically requires resolving numerous ambiguities. Existing sketch-based modeling methods handle these ambiguities by either relying on expensive user annotations or by restricting the modeled shapes to specific narrow categories. We present an approach for modeling generic freeform 3D surfaces from sparse, expressive 2D sketches that overcomes both limitations by incorporating convolution neural networks (CNN) into the sketch processing workflow. Given a 2D sketch of a 3D surface, we use CNNs to infer the depth and normal maps representing the surface. To combat ambiguity we introduce an intermediate CNN layer that models the dense curvature direction, or flow, field of the surface, and produce an additional output confidence map along with depth and normal. The flow field guides our subsequent surface reconstruction for improved regularity; the confidence map trained unsupervised measures ambiguity and provides a robust estimator for data fitting. To reduce ambiguities in input sketches users can refine their input by providing optional depth values at sparse points and curvature hints for strokes. Our CNN is trained on a large dataset generated by rendering sketches of various 3D shapes using non-photo-realistic line rendering (NPR) method that mimics human sketching of free-form shapes. We use the CNN model to process both single- and multi-view sketches. Using our multi-view framework users progressively complete the shape by sketching in different views, generating complete closed shapes. For each new view, the modeling is assisted by partial sketches and depth cues provided by surfaces generated in earlier views. The partial surfaces are fused into a complete shape using predicted confidence levels as weights.
Authors/Presenter(s): Changjian Li, The University of Hong Kong, Microsoft Research Asia, Hong Kong
Hao Pan, Microsoft Research Asia, China
Yang Liu, Microsoft Research Asia, China
Xin Tong, Microsoft Research Asia, China
Alla Sheffer, University of British Columbia, Canada
Wenping Wang, The University of Hong Kong, Hong Kong

ALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning
Abstract: The process of aligning a pair of shapes is a fundamental operation in computer graphics. Traditional approaches rely heavily on matching corresponding points or features to guide the alignment, a paradigm that falters when significant shape portions are missing. These techniques generally do not incorporate prior knowledge about expected shape characteristics, which can help compensate for any misleading cues left by inaccuracies exhibited in the input shapes. We present an approach based on a deep neural network, leveraging shape datasets to learn a shape-aware prior for source-to-target alignment that is robust to shape incompleteness. In the absence of ground truth alignments for supervision, we train a network on the task of shape alignment using incomplete shapes generated from full shapes for self-supervision. Our network, called ALIGNet, is trained to warp complete source shapes to incomplete targets, as if the target shapes were complete, thus essentially rendering the alignment partial-shape agnostic. We aim for the network to develop specialized expertise over the common characteristics of the shapes in each dataset, thereby achieving a higher-level understanding of the expected shape space to which a local approach would be oblivious. We constrain ALIGNet through an anisotropic total variation identity regularization to promote piecewise smooth deformation fields, facilitating both partial-shape agnosticism and post-deformation applications. We demonstrate that ALIGNet learns to align geometrically distinct shapes, and is able to infer plausible mappings even when the target shape is significantly incomplete. We show that our network learns the common expected characteristics of shape collections, without over-fitting or memorization, enabling it to produce plausible deformations on unseen data during test time.
Authors/Presenter(s): Rana Hanocka, Tel Aviv University, Israel
Noa Fish, Tel Aviv University, Israel
Zhenhua Wang, Hebrew University, Israel
Raja Giryes, Tel Aviv University, Israel
Shachar Fleishman, Intel Corporation, Israel
Daniel Cohen-Or, Tel Aviv University, Israel

