-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Wednesday, December 5th
Time: 9:00am - 10:45am
Venue: Hall B5(1) (5F, B Block)
Session Chair(s): Andy Nealen, TBU,
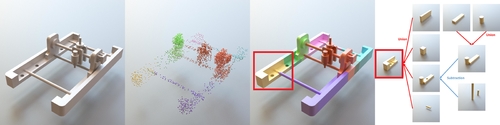
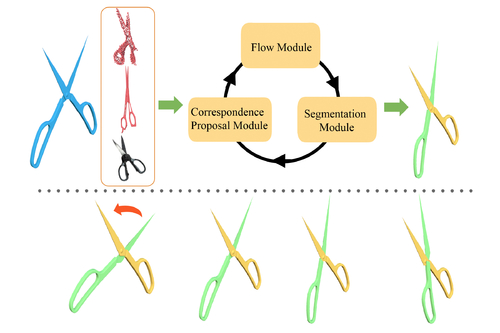
Deep Part Induction from Articulated Object Pairs
Abstract: Object functionality is often expressed through part articulation -- as when the two rigid parts of a scissor pivot against each other to accomplish the cutting function. Such articulations are often consistent across objects within the same underlying functional category. In this paper we explore how the observation of different articulation states provides evidence for part structure of 3D objects. We start from a pair of unsegmented 3D CAD models or scans, or a pair of a 3D shape and an RGB image, indicating two different articulation states of two functionally related objects and aim to induce their common part structure. This is a challenging setting, as we assume no prior shape structure, the articulation states may belong to objects of different geometry, plus we allow noisy and partial scans as input. Our method learns a neural network architecture with three modules that respectively propose correspondences, estimate 3D deformation flows, and perform segmentation. As we demonstrate, when our architecture is iteratively used in an ICP-like fashion alternating between correspondence, flow, and segmentation prediction, it significantly outperforms state-of-the-art techniques in the task of discovering articulated parts of objects. We note that our part induction is object-class agnostic and generalizes well to new and unseen objects.
Authors/Presenter(s): Li Yi, Stanford University, United States of America
Haibin Huang, Face++ (Megvii), United States of America
Difan Liu, University of Massachusetts Amherst, United States of America
Evangelos Kalogerakis, University of Massachusetts Amherst, United States of America
Hao Su, University of California San Diego, United States of America
Leonidas Guibas, Stanford University, United States of America
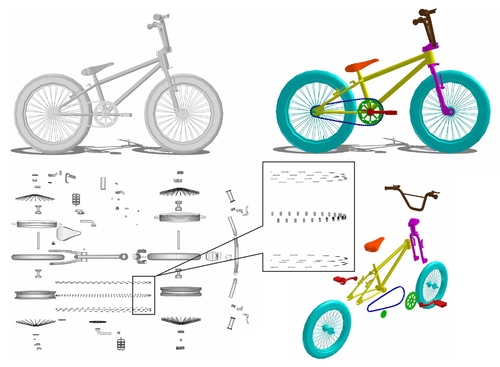
Learning to Group and Label Fine-Grained Shape Components
Abstract: A majority of stock 3D models in modern shape repositories are assembled with many fine-grained components. The main cause of such data form is the component-wise modeling process widely practiced by human modelers. These modeling components thus inherently reflect some function-based shape decomposition the artist had in mind during modeling. On the other hand, modeling components represent an over-segmentation since a functional part is usually modeled as a multi-component assembly. Based on these observations, we advocate that labeled segmentation of stock 3D models should not overlook the modeling components and propose a learning solution to grouping and labeling of the fine-grained components. However, directly characterizing the shape of individual components for the purpose of labeling is unreliable, since they can be arbitrarily tiny and semantically meaningless. We propose to generate part hypotheses from the components based on a hierarchal grouping strategy, and perform labeling on those part groups instead of directly on the components. Part hypotheses are mid-level elements which are more probable to carry semantic information. A multiscale 3D convolutional neural network is trained to extract context-aware features for the hypotheses. To accomplish a labeled segmentation of the whole shape, we formulate higher-order conditional random fields (CRFs) to infer an optimal label assignment for all components. Extensive experiments demonstrate that our method achieves significantly robust labeling results on raw 3D models from public shape repositories. Our work also contributes the first benchmark for component-wise labeling.
Authors/Presenter(s): Xiaogang Wang, Beihang University, China
Bin Zhou, Beihang University, China
Haiyue Fang, Beihang University, China
Xiaowu Chen, Beihang University, China
Qinping Zhao, Beihang University, China
Kai Xu, National University of Defense Technology, Princeton University, United States of America
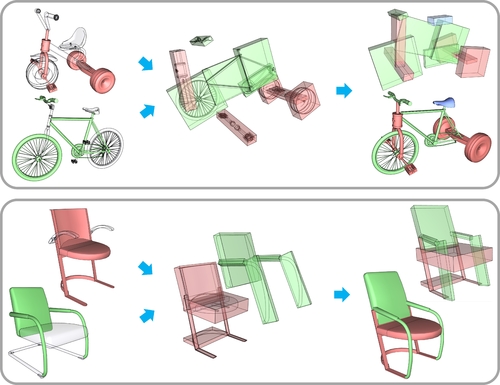
SCORES: Shape Composition with Recursive Substructure Priors
Abstract: We introduce SCORES, a recursive neural network for shape composition. Our network takes as input sets of parts from two or more source 3D shapes and a rough initial placement of the parts. It outputs an optimized part structure for the composed shape, leading to high-quality geometry construction. A unique feature of our composition network is that it is not merely learning how to connect parts. Our goal is to produce a coherent and plausible 3D shape, despite large incompatibilities among the input parts. The network may significantly alter the geometry and structure of the input parts and synthesize a novel shape structure based on the inputs, while adding or removing parts to minimize a structure plausibility loss. We design SCORES as a recursive autoencoder network. During encoding, the input parts are recursively grouped to generate a root code. During synthesis, the root code is decoded, recursively, to produce a new, coherent part assembly. Assembled shape structures may be novel, with little global resemblance to training exemplars, yet have plausible substructures. SCORES therefore learns a hierarchical substructure shape prior based on per-node losses. It is trained on structured shapes from ShapeNet, and is applied iteratively to reduce the plausibility loss. We show results of shape composition from multiple sources over different categories of man-made shapes and compare with state-of-the-art alternatives, demonstrating that our network can significantly expand the range of composable shapes for assembly-based modeling.
Authors/Presenter(s): Chenyang Zhu, Simon Fraser University, National University of Defense Technology, Canada
Kai Xu, National University of Defense Technology, Princeton University, United States of America
Siddhartha Chaudhuri, Adobe Research, IIT Bombay, India
Renjiao Yi, Simon Fraser University, National University of Defense Technology, Canada
Hao Zhang, Simon Fraser University, Canada
Language-Driven Synthesis of 3D Scenes from Scene Databases
Abstract: We introduce a novel framework for using natural language to generate and edit 3D indoor scenes, harnessing scene semantics and text-scene grounding knowledge learned from large annotated 3D scene databases. The advantage of natural language editing interfaces is strongest when performing semantic operations at the sub-scene level, acting on groups of objects. We learn how to manipulate these sub-scenes by analyzing existing 3D scenes. We perform edits by first parsing a natural language command from the user and transforming it into a semantic scene graph that is used to retrieve corresponding sub-scenes from the databases that match the command. We then augment this retrieved sub-scene by incorporating other objects that may be implied by the scene context. Finally, a new 3D scene is synthesized by aligning the augmented sub-scene with the user's current scene, where new objects are spliced into the environment, possibly triggering appropriate adjustments to the existing scene arrangement. A suggestive modeling interface with multiple interpretations of user commands is used to alleviate ambiguities in natural language. We conduct studies comparing our approach against both prior text-to-scene work and artist-made scenes and find that our method significantly outperforms prior work and is comparable to handmade scenes even when complex and varied natural sentences are used.
Authors/Presenter(s): Rui Ma, Simon Fraser University, AltumView Systems Inc., Canada
Akshay Gadi Patil, Simon Fraser University, Canada
Matthew Fisher, Adobe Research, United States of America
Manyi Li, Shandong University, Simon Fraser University, China
Sören Pirk, Stanford University, United States of America
Binh-Son Hua, University of Tokyo, Japan
Sai-Kit Yeung, Hong Kong University of Science and Technology, Hong Kong
Xin Tong, Microsoft Research Asia, China
Leonidas Guibas, Stanford University, United States of America
Hao Zhang, Simon Fraser University, Canada

InverseCSG: Automatic Conversion of 3D Models to CSG Trees
Abstract: While computer-aided design is a major part of many modern manufacturing pipelines, the design files generated describe raw geometry. Lost in this representation is the procedure by which these designs were generated. In this paper, we present a method for reverse-engineering the process by which 3D models may have been generated, in the language of constructive solid geometry (CSG). Observing that CSG is a formal grammar, we formulate this inverse CSG problem as a program synthesis problem. Our solution is an algorithm that couples geometric processing with state-of-the-art program synthesis techniques. In this scheme, geometric processing is used to convert the mixed discrete and continuous domain of CSG trees to a pure discrete domain that modern program synthesizers excel in. We prove that our algorithm provides a complete search and demonstrate its efficiency and scalability on several different examples, including those with over $100$ primitive parts. We show that our algorithm is able to find simple programs which are close to the ground truth, and demonstrate our method's applicability in mesh re-editing. Finally, we compare our method to prior state-of-the-art. We demonstrate that our algorithm dominates previous methods in terms of resulting CSG compactness and runtime, and can handle far more complex input meshes than any previous method.
Authors/Presenter(s): Andrew Spielberg, Massachusetts Institute of Technology, United States of America
Adriana Schulz, Massachusetts Institute of Technology, United States of America
Daniela Rus, Massachusetts Institute of Technology, United States of America
Armando Solar-Lezama, Massachusetts Institute of Technology, United States of America
Wojciech Matusik, Massachusetts Institute of Technology, United States of America
Tao Du, Massachusetts Institute of Technology, United States of America
Jeevana Priya Inala, Massachusetts Institute of Technology, United States of America
Yewen Pu, Massachusetts Institute of Technology, United States of America