
-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Wednesday, December 5th
Time: 9:00am - 10:45am
Venue: Hall B5(2) (5F, B Block)
Session Chair(s): Baoquan Chen, Shandong University, Advanced Innovation Center for Future Visual Entertainment, China
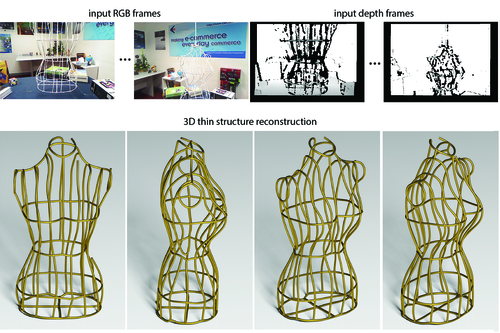
CurveFusion: Reconstructing Thin Structures from RGBD Sequences
Abstract: We introduce CurveFusion, the first approach for high quality scanning of thin structures at interactive rates using a handheld RGBD camera. Thin filament-like structures are mathematically just 1D curves embedded in R^3, and integration-based reconstruction works best when depth sequences (from the thin structure parts) are fused using the object's (unknown) curve skeleton. Thus, using the complementary but noisy color and depth channels, CurveFusion first automatically identifies point samples on potential thin structures and groups them into bundles, a fixed number of aligned consecutive frames. Then, the algorithm extracts per bundle skeleton curves using one axes and aligns and iteratively merges the one segments from each bundle to form the final complete curve skeleton. Unlike previous methods, reconstruction happens via integration along a data-dependent fusion primitive, i.e., the extracted curve skeleton. We extensively evaluate CurveFusion on a range of challenging examples, different scanner and calibration settings, and present high fidelity thin structure reconstructions previously just not possible with the existing reconstruction methods from raw RGBD sequences
Authors/Presenter(s): Lingjie Liu, University of Hong Kong, University College London, Hong Kong
Nenglun Chen, University of Hong Kong, Hong Kong
Duygu Ceylan, Adobe Research, United States of America
Christian Theobalt, Max Planck Institute for Informatics, Germany
Wenping Wang, University of Hong Kong, Hong Kong
Niloy J. Mitra, University College London, United Kingdom
Semantic Object Reconstruction via Casual Handheld Scanning
Abstract: We introduce a learning-based method to reconstruct objects acquired in a casual handheld scanning setting with a depth camera. Our method is based on two core components. First, a deep network that provides a semantic segmentation and labeling of the frames of an input RGBD sequence. Second, an alignment and reconstruction method that employs the semantic labeling to reconstruct the acquired object from the frames. We demonstrate that the use of a semantic labeling improves the reconstructions of the objects, when compared to methods that use only the depth information of the frames. Moreover, since training a deep network requires a large amount of labeled data, a key contribution of our work is an active self-learning framework to simplify the creation of the training data. Specifically, we iteratively predict the labeling of frames with the neural network, reconstruct the object from the labeled frames, and evaluate the confidence of the labeling, to incrementally train the neural network while requiring only a small amount of user-provided annotations. We show that this method enables the creation of data for training a neural network with high accuracy, while requiring only little manual effort.
Authors/Presenter(s): Ruizhen Hu, Shenzhen University, China
Cheng Wen, Shenzhen University, China
Oliver van Kaick, Carleton University, Canada
Luanmin Chen, Shenzhen University, China
Di Lin, Shenzhen University, China
Daniel Cohen-Or, Shenzhen University, Tel Aviv University, Israel
Hui Huang, Shenzhen University, China

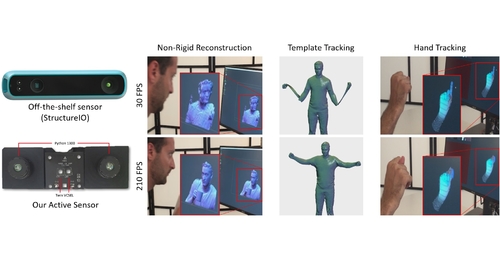
The Need 4 Speed in Real-Time Dense Visual Tracking
Abstract: The advent of consumer depth cameras has incited the development of a new cohort of algorithms tackling challenging computer vision problems. The primary reason is that depth provides direct geometric information that is largely invariant to texture and illumination. As such, substantial progress has been made in human and object pose estimation, 3D reconstruction and simultaneous localization and mapping. Most of these algorithms naturally benefit from the ability to accurately track the pose of an object or scene of interest from one frame to the next. However, commercially available depth sensors (typically running at 30fps) can allow for large inter-frame motions to occur that make such tracking problematic. This paper proposes a novel combination of hardware and software components that avoids the need to compromise between a dense accurate depth map and a high frame rate. We document the creation of a full 3D capture system for high speed and quality depth estimation, and demonstrate its advantages in a variety of tracking and reconstruction tasks. We extend the state of the art active stereo algorithm presented in Fanello et al. [2017b] by adding a space-time feature in the matching phase. We also propose a machine learning based depth refinement step that is an order of magnitude faster than traditional post-processing methods. We quantitatively and qualitatively demonstrate the benefits of the proposed algorithms in the acquisition of geometry in motion. Our pipeline executes in 1.1ms leveraging modern GPUs and off-the-shelf cameras and illumination components. We show how the sensor can be employed in many different applications, from [non-]rigid reconstructions to hand/face tracking. Further, we show many advantages over existing state of the art depth camera technologies beyond framerate, including latency, motion artifacts, multi-path errors, and multi-sensor interference.
Authors/Presenter(s): Adarsh Kowdle, Google, United States of America
Christoph Rhemann, Google, United States of America
Sean Fanello, Google, United States of America
Andrea Tagliasacchi, Google, United States of America
Jonathan Taylor, Google, United States of America
Philip Davidson, Google, United States of America
Mingsong Dou, Google, United States of America
Kaiwen Guo, Google, United States of America
Cem Keskin, Google, United States of America
Sameh Khamis, Google, United States of America
David Kim, Google, United States of America
Danhang Tang, Google, United States of America
Vladimir Tankovich, Google, United States of America
Julien Valentin, Google, United States of America
Shahram Izadi, Google, United States of America
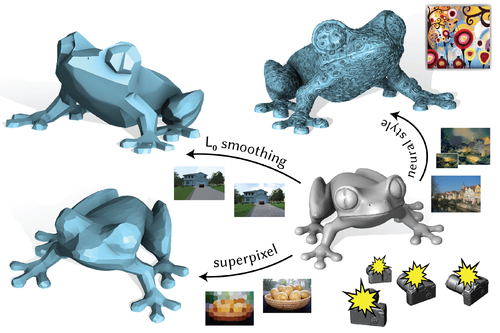
Paparazzi: Surface Editing by way of Multi-View Image Processing
Abstract: The image processing pipeline boasts a wide variety of complex filters and effects. Translating an individual effect to operate on 3D surface geometry inevitably results in a bespoke algorithm. Instead, we propose a general-purpose back-end optimization that allows users to edit an input 3D surface by simply selecting an off-the-shelf image processing filter. We achieve this by constructing a differentiable triangle mesh renderer, with which we can back propagate changes in the image domain to the 3D mesh vertex positions. The given image processing technique is applied to the entire shape via stochastic snapshots of the shape: hence, we call our method Paparazzi. We provide simple yet important design considerations to construct the Paparazzi renderer and optimization algorithms. The power of this rendering-based surface editing is demonstrated via the variety of image processing filters we apply. Each application uses an off-the-shelf implementation of an image processing method without requiring modification to the core Paparazzi algorithm.
Authors/Presenter(s): Hsueh-Ti Derek Liu, University of Toronto, Canada
Michael Tao, University of Toronto, Canada
Alec Jacobson, University of Toronto, Canada
Real-time High-accuracy 3D Reconstruction with Consumer RGB-D Cameras
Abstract: We present an integrated approach for reconstructing high-fidelity three-dimensional (3D) models using consumer RGB-D cameras. RGB-D registration and reconstruction algorithms are prone to errors from scanning noise, making it hard to perform 3Dreconstruction accurately. The key idea of our method is to assign a probabilistic uncertainty model to each depth measurement, which then guides the scan alignment and depth fusion. This allows us to effectively handle inherent noise and distortion in depth maps while keeping the overall scan registration procedure under the iterative closest point framework for simplicity and efficiency. We further introduce a local-to-global, submap-based, and uncertainty-aware global pose optimization scheme to improve scalability and guarantee global model consistency. Finally, we have implemented the proposed algorithm on the GPU, achieving real-time 3D scanning frame rates and updating the reconstructed model on-the-fly. Experimental results on simulated and real-world data demonstrate that the proposed method outperforms state-of-the-art systems in terms of the accuracy of both recovered camera trajectories and reconstructed models.
Authors/Presenter(s): Yan-Pei Cao, Tsinghua University, Owlii Inc., China
Leif Kobbelt, RWTH Aachen University, Germany
Shimin Hu, Tsinghua University, Cardiff University, China

