
-
 Full Conference Pass (FC)
Full Conference Pass (FC)
-
 Full Conference One-Day Pass (1D)
Full Conference One-Day Pass (1D)
Date: Thursday, December 6th
Time: 9:00am - 10:45am
Venue: Hall D5 (5F, D Block)
Session Chair(s): Jehee Lee, Seoul National University, Movement Research Lab., South Korea
Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
Abstract: We demonstrate a novel deep neural network capable of reconstructing human full body pose in real-time from 6 Inertial Measurement Units (IMUs) worn on the user’s body. In doing so, we address several difficult challenges. First, the problem is severely under-constrained as multiple pose parameters produce the same IMU orientations. Second, capturing IMU data in conjunction with ground-truth poses is expensive and difficult to do in many target application scenarios (e.g., outdoors). Third, modeling temporal dependencies through non-linear optimization has proven effective in prior work but makes real-time prediction infeasible. To address this important limitation, we learn the temporal pose priors using deep learning. To learn from sufficient data, we synthesize IMU data from motion capture datasets. A bi-directional RNN architecture leverages past and future information that is available at training time. At test time, we deploy the network in a sliding window fashion, retaining real time capabilities. To evaluate our method, we recorded DIP-IMU, a dataset consisting of 10 subjects wearing 17 IMUs for validation in 64 sequences with 330 000 time instants; this constitutes the largest IMU dataset publicly available. We quantitatively evaluate our approach on multiple datasets and show results from a real-time implementation. DIP-IMU and the code are available for research purposes (http://dip.is.tuebingen.mpg.de).
Authors/Presenter(s): Yinghao Huang, Max Planck Institute for Intelligent Systems, Germany
Manuel Kaufmann, ETH Zurich, Switzerland
Emre Aksan, ETH Zurich, Switzerland
Michael J. Black, Max Planck Institute for Intelligent Systems, Germany
Otmar Hilliges, ETH Zurich, Switzerland
Gerard Pons-Moll, Max Planck Institute for Informatik, Germany

Crowd Space: A Predictive Crowd Analysis Technique
Abstract: Over the last two decades there has been a proliferation of methods for simulating crowds of humans. As the number of different methods and their complexity increases, it becomes increasingly unrealistic to expect researchers and users to keep up with all the possible options and trade-offs. We therefore see the need for tools that can facilitate both domain experts and non-expert users of crowd simulation in making high-level decisions about the best simulation methods to use in different scenarios. In this paper, we leverage trajectory data from human crowds and machine learning techniques to learn a manifold which captures representative local navigation scenarios that humans encounter in real life. We show the applicability of this manifold in crowd research, including analyzing trends in simulation accuracy, and creating automated systems to assist in choosing an appropriate simulation method for a given scenario.
Authors/Presenter(s): Ioannis Karamouzas, Clemson University, United States of America
Nick Sohre, University of Minnesota, United States of America
Ran Hu, Facebook, University of Minnesota, United States of America
Stephen J. Guy, University of Minnesota, United States of America
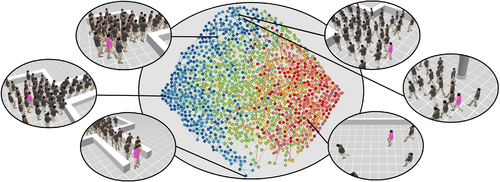
Deep Motifs and Motion Signatures
Abstract: Many analysis tasks for human motion rely on high-level similarity between sequences of motions, that are not an exact matches in joint angles, timing, or ordering of actions. Even the same movements performed by the same person can vary in duration and speed. Similar motions are characterized by similar sets of actions that appear frequently. In this paper we introduce motion motifs and motion signatures that are a succinct but descriptive representation of motion sequences. We first break the motion sequences to short-term movements called motion words, and then cluster the words in a high-dimensional feature space to find motifs. Hence, motifs are words that are both common and descriptive, and their distribution represents the motion sequence. To define a signature, we choose a finite set of motion-motifs, creating a bag-of-motifs representation for the sequence. Motion signatures are agnostic to movement order, speed or duration variations, and can distinguish fine-grained differences between motions of the same class. To cluster words and find motifs, the challenge is to define an effective feature space, where the distances among motion words are semantically meaningful, and where variations in speed and duration are handled. To this end, we use a deep neural network to embed the motion words into feature space using a triplet loss function. We illustrate examples of characterizing motion sequences by motifs, and for the use of motion signatures in a number of applications.
Authors/Presenter(s): Andreas Aristidou, The Interdisciplinary Center, University of Cyprus, Israel
Daniel Cohen-Or, Tel Aviv University, Israel
Jessica Hodgins, Carnegie Mellon University, United States of America
Yiorgos Chrysanthou, University of Cyprus, RISE Research Center, Cyprus
Ariel Shamir, The Interdisciplinary Center, Israel

Tracking the Gaze on Objects in 3D -- How do People Really Look at the Bunny?
Abstract: We provide the first large dataset of human fixations on physical 3D objects presented in varying viewing conditions and made of different materials. Our experimental setup is carefully designed to allow for accurate calibration and measurement. We estimate a mapping from the pair of pupil positions to 3D coordinates in space and register the presented shape with the eye tracking setup. By modeling the fixated positions on 3D shapes as a probability distribution, we analysis the similarities among different conditions. The resulting data indicates that salient features are stable across viewing directions only if they are semantic. We also show that it is possible to estimate the gaze density maps from view dependent data. The dataset provides the necessary ground truth data for computational models of human perception in 3D.
Authors/Presenter(s): Xi Wang, TU Berlin, Germany
Sebastian Koch, TU Berlin, Germany
Kenneth Holmqvist, Regensburg University, Germany
Marc Alexa, TU Berlin, Germany

